User fingerprinting with Markov chains
I’ve had an interest in the unique way each individual types for a long time, almost a digital accent that can identify you to a group of people. The way you use emojis, and capitalization, and punctuation can quickly sort you into an age demographic by a viewer in a matter of seconds. You need text if you understand the meaning or not to already start building a mental model of who someone is.
This blog post describes how I automated this process of identification via text and explore its ramifications.
A primer on Markov chains
If you’re reading this blog post you may have a decent understanding on Markov chains, if that is the case feel free to skip this section.
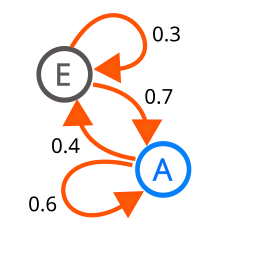
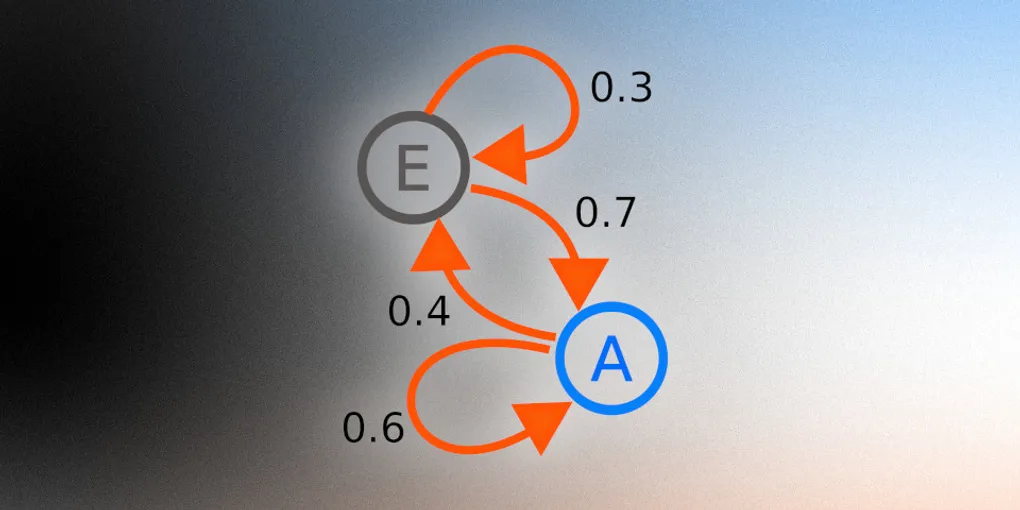
Markov chains are models of probability, with nodes representing events and edges representing the probability of one event happening after another. They have a whole bunch of nerdy uses that probably saves lives that you can read about on Wikipedia, which to be completely honest I am severely under qualified to talk about. Where you probably have actually seen Markov chains before are in the little typing suggestion box above your mobile keyboard.
This was likely done with a fairly common text generation method in a pre-LLM world.
So first you take a collection text from whatever source you’re aiming to imitate, and tokenize it out.
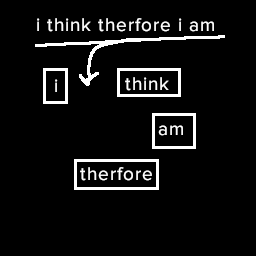
These tokens become the nodes of our graph, and we can connect them up by their sequence in the text. Then weight them based on the likelihood of that token pair appearing in the text.
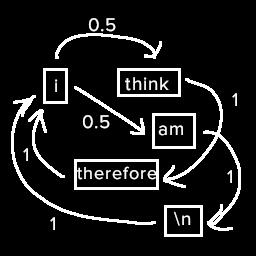
If we traverse this graph we either get “i think therefore i am” or “i am”. Riveting stuff, but as you go to larger and larger data sets it creates more novel but still meaningless sentences.
Identification
So if we can get messages out of the Markov chain and see the probability of each step, why can’t we reverse the process and see how close any message matches the Markov chain. So a quick addition to the Markov chain code I loop through the pairs of tokens and check the score between the two then average all the scores out to produce a final score. The implementation was so easy, I got a proof of concept working in about afternoon. I felt a bit bad for how simple the project was and started adding CSV processing features just to fluff it up.
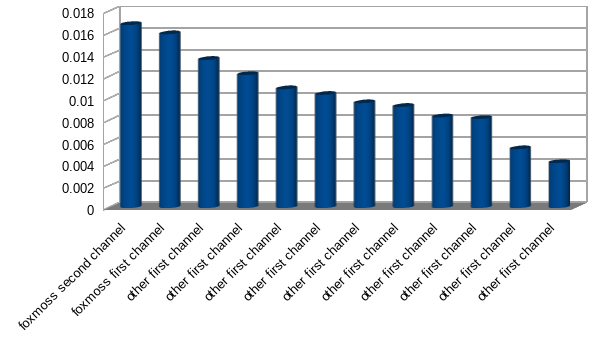
So does it work? Some preliminary tests were encouraging, and eventually I got exports from Discord working. The chain flawless ranked ranked my messages from two different channels when compared to 10 other users messages.
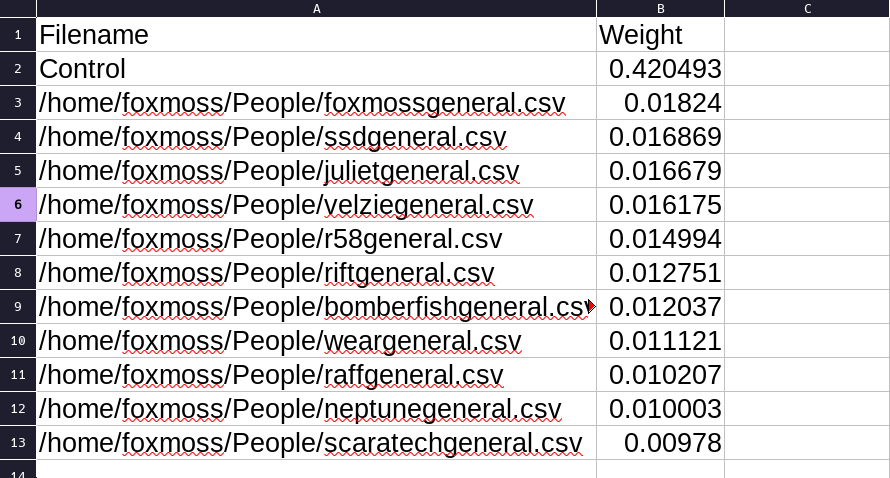
Now admittedly this is a bit hard to parse out, humans aren’t great at visualizing numbers.
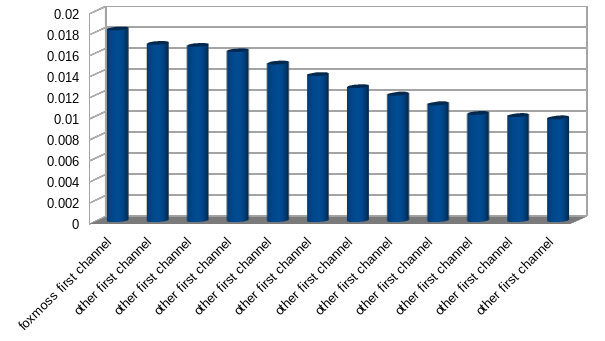
This makes it a bit clearer, the correct answers are only ahead by a small margin. This is to be expected, it’s a statistical model and English text will likely find itself falling into similar patterns, but whats good is there’s a visible difference where you can see where it matches and where it doesn’t.
Comparing the same people to a random person in the data:
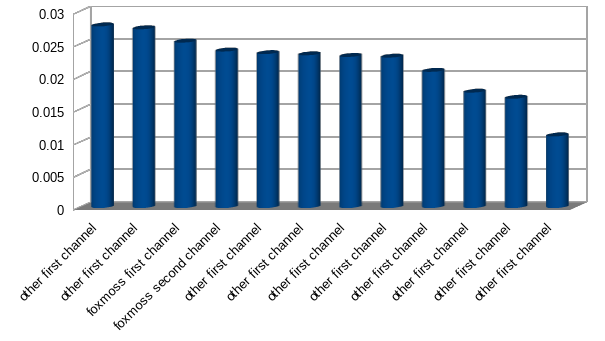
It looks basically the same, great. There’s some change in the data when two message sources are written by the same person.
Now how would I quantify this difference to prevent false positives in an purely automated system is beyond me. I would like to do more testing on just the raw accuracy but finding data on a larger scale, especially while keeping all parties involved consenting. So I will leave further research past “Does it work?” as an exercise for the reader, or for a later blog.
Avoiding detection
I attempted the original test again but this time with an alt account on a different server where I was intentionally speaking different, even with this the result came back as accurate as before, maybe even more clear cut.
But typing different likely does have an effect as I took these messages on an alt account and ran them through the Claude (though likely any LLM would work) and got it to rephrase my messages. After running it through the chain again something quite interesting happened.
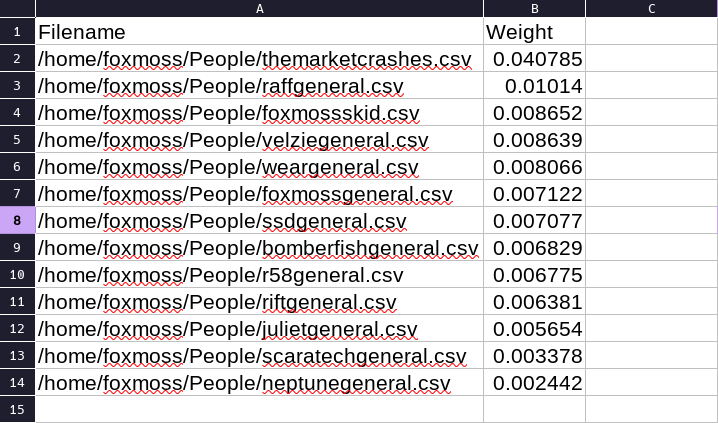
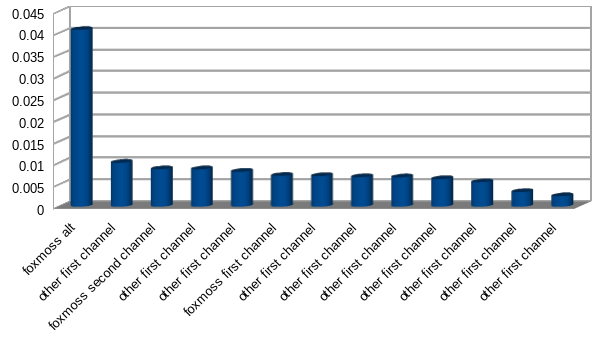
The new Claude dataset matched closely with the alt dataset which make sense but not my other datasets. More testing is of course needed but using an AI to reformat right now seems like a good way to mask your typing style.
Though a problem might arise as you try not navigate having more identities as the new AI guided typing style is now likely equally detectable.
Conclusion
Here’s a link to my implementation. Feel free to contribute.
Shout out to Mercury Workshop for helping with data collection.